Ieri sera, mi chiama al telefono mia zia. Cosa centra col web scraping?
Solitamente mi contatta quando qualche virus gli ha infettato il pc, allora io con grande solerzia devo correre a sistemare l’invasione dei “cyber-criminali”.
Questa volta però la richiesta è stata al quanto bizzarra. daweb b
Mi ha chiesto di scaricargli dal web tutti gli indirizzi e numeri di telefono delle Chiese Evangeliche italiane. Vuole inviare a tutti gli auguri pasquali, nessuno escluso.
Questa volta però la richiesta è stata al quanto bizzarra. daweb b
Mi ha chiesto di scaricargli dal web tutti gli indirizzi e numeri di telefono delle Chiese Evangeliche italiane. Vuole inviare a tutti gli auguri pasquali, nessuno escluso.

Dieci minuti di smarrimento interiore.
La prima cosa che mi è venuta in mente è stata la tecnica nota con il nome di “web scraping”.
Che cosa è il web scraping?
E’ una tecnica informatica di estrazione dati da siti web, per mezzo di software strutturati ad hoc.
Il dato è ricchezza, l’informazione estratta, aggregata, rielaborata e collezionata è vitale per gli ecosistemi informatici.
Sistemi che utilizziamo per il business, per attività scientifiche o per analisi di mercato.
Perchè fare web scraping?
Strutturare informazioni non strutturate, velocizzando ed ottimizzando procedure e flussi dati con il web scraping è pratico, semplice, veloce.
In alcuni casi bastano poche righe di codice per accedere a dati, il cui interfacciamento richiederebbe tempo e denaro.
Il web scraping può essere eseguito anche attraverso API, ove disponibili, garantendo ai programmatori più esperti, maggior dinamismo nelle richieste effettuate per estrapolare informazioni.
Web scraping “umano”
L’essere umano naviga sul web, legge, acquisisce informazioni, copia e incolla parti di testo, prende appunti e salva immagini a lui gradite. Lo scraping umano ha evidentemente delle enormi limitazioni.
L’imprenditore alla ricerca di informazioni per il proprio business o il biologo a caccia di dati utili per lavorare ad una ricerca scientifica, si trovano dinanzi alla stessa necessità.
Rendere performanti, tutte quelle operazioni legate all’estrazione, acquisizione e manipolazione dei dati, attraverso l’adozione di software dedicati.
Web scraping via software
Esistono moltissimi strumenti, librerie e software per realizzare soluzioni personalizzate in grado di effettaure web scraping (o web data extraction).
Preso da una irrefrenabile voglia di smanettare, sono andato sul sito web di evangelici.netper approfondire la faccenda.
Ho trovato subito una pagina dedicata alla ricerca delle sedi presenti in Italia.
Ricerca che appare abbastanza semplice, ma avendo 2400 sedi circa è imporponibile fare copia e incolla di tutto. E’ sufficiente imbastire un programmino per acquisire le informazioni richieste dalla zia, evitando così di dover fare un ctrl+c e ctrl+v di tutti i dati.
Quello che maggiormente mi ha colpito è stata la nota presente nel footer del sito web:” Il materiale presente in questa pagina si può ripubblicare liberamente ma solo a queste condizioni”. (Per capire meglio, leggete tutta la pagina delle condizioni di utilizzo).
Web scraping e le condizioni d’utilizzo?
In sintesi: il testo che utilizzi non è tuo, è di qualcuno che ha lavorato seriamente per realizzarlo al meglio delle sue possibilità per esserti di benedizione. Puoi usufruirne quanto ne vuoi, ma non ti è stato regalato: ti viene prestato gratuitamente. Sii corretto, usalo con rispetto. […e non per scopi commerciali]
Ringrazio con affetto gli amici di evangelici.net, il loro sito web è un importante esempio di condivisione di contenuti per finalità non commerciali.
Una piattaforma a cui approcciarsi con rispetto e con le dovute cautele tecniche.
Questo tipo di approccio Open Source dei contenuti ci consente di avviare un’analisi più ampia in merito al web scraping, tecnica spesso opaca per acquisire dati e informazioni.
Molteplici sono gli elementi da prendere in considerazione, quando vogliamo utilizzare questa procedura di estrazione dati da siti web.
Tralasciando l’aspetto economico e focalizzando l’attenzione su aspetti di tipo tecnico e legale, appare subito evidente che la semplicità con cui si possono estrarre dati, spesso è in forte contrasto con la possibilità di effettuare l’estrazione legalmente.
Ho inziato a scrivere questo post spinto dall’esigenza di capire e delineare i confini legali dello scraping, cercando allo stesso tempo di analizzare le pratiche legate agli strumenti più utilizzati per estrarre informazioni.
Alla fine mi sono ritrovato ad affrontare il classico problema etico legato a: privacy, produttori, possessori e detentori dei dati personali.
Quindi fare web scraping è legale o illegale?
“The quieter you become, the more you are able to hear”
L’aforisma dello psicologo statunitense Richard Alpert, utilizzato come vessillo dal Sistema Operativo Kali Linux (in precedenza BackTrack), è sicuramente la migliore rappresentazione concettuale, per un corretto approccio “tecnico” al web scraping.
Più sei silenzioso, meglio riesci a sentire…(meno rumore fai, maggiori possibilità avrai di non essere sgamato).
Facciamo molta attenzione, le tecniche informatiche che consentono di diventare “silenziosi” e/o “invisibili” non devono portarci a sottovalutare elementi chiave come normativa, condizioni contrattuali, termini d’utilizzo del sito web, ma anche privacy e autorizzazione alla raccolta, manipolazione e diffusione dei dati raccolti.
L’importanza delle condizioni di utilizzo di un sito web
Enorme è il peso che hanno in un sito web, elementi contrattuali vincolanti come “Privacy degli utenti” e “Condizioni d’utilizzo”, in quanto applicazione diretta di normative nazionali, europee (vedi GDPR) o internazionali.
Ecco perchè (solo dopo aver letto le condizioni di utilizzo) ipotizziamo di poter acquisire dati in maniera automatizzata sul sito web evangelici.net, procedura chead esempio non è possibile utilizzare sul sito web di pagine Pagine Gialle.
A questo punto per capire meglio esaminiamo un passo esaustivo delle note legali di PagineGialle:
LIMITI DI UTILIZZO
I dati ricavabili dal presente servizio sono contenuti in una banca dati protetta ai sensi e per gli effetti della legge sul diritto d’autore. Sono pertanto vietati, fra l’altro, la riproduzione ed il trasferimento, totale o parziale, con qualsiasi mezzo dei suddetti dati.Sono comunque vietate le operazioni di estrazione e di reimpiego della totalità o di una parte sostanziale della stessa banca dati, nonchè l’estrazione o il reimpiego di parti non sostanziali del suo contenuto qualora tali attività siano ripetute e sistematiche.
Link: https://www.paginegialle.it/termini-condizioni/note_legali
Pagine Gialle a differenza di evangelici.net ci dice che:
1. la loro banca dati è normata ai sensi di legge
2. è vietata la riproduzione totale o parziale ed il trasferimento con qualsiasi mezzo (quindi neanche con matita su foglio di carta)
3. sono vietate le operazioni di estrazione e reimpiego di parti sostanziali totali o parziali, ma non solo anche di parti non sostanziali (qualora ripetute e sistematiche)
Altri riferimenti e indicazioni di carattere legale:
Garante della Privacy, Italia — NEWSLETTER N. 411 del 4 febbraio 2016:
Tlc, no alla pesca a strascico sul web per formare gli elenchi telefonici
Il Garante blocca un sito che trattava in modo illecito i dati di oltre 12 milioni di persone…
Link: https://www.garanteprivacy.it/web/guest/home/docweb/-/docweb-display/docweb/4644612
Con questo provvedimento il Garante ha confermato che per creare elenchi telefonici, anche online, occorre seguire le regole dettate dallo stesso Garante nel corso del tempo, utilizzando il database unico che raccoglie numeri di telefono e altri dati dei clienti di tutti gli operatori nazionali di telefonia fissa e mobile o in alternativa, acquisendo il consenso libero, informato, specifico da parte degli utenti.
Alcune tra le più importanti sentenze americane in materia di web scraping:
2000 eBay v. Bidder’s Edge (* risolto in via extragiudiziale)
2009 Facebook v. Power.com
2010 Cvent, Inc. v. Eventbrite, Inc.
2013 The Associated Press contro Meltwater US Holdings

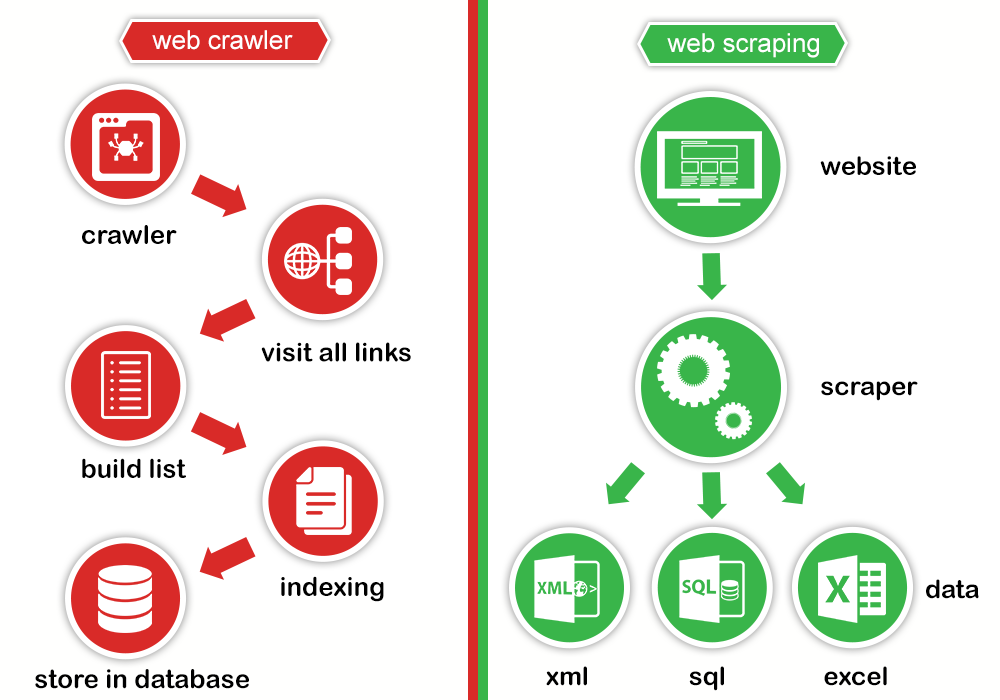
Il web scraping e il web crawling
Quando si parla di web scraping è opportuno menzionare anche il web crawling, che utilizza elementi e logiche comuni, ma non estrae dati, si occupa di scansionare e indicizzare contenuti, che verranno collocati nelle directory dei motori di ricerca.
I Crawler vengono strutturati con lo scopo di impattare il meno possibile sulle risorse server, a differenza degli Scraper che in alcuni casi vengono realizzati per operare in maniera anonima, cercando di concludere, un lavoro non sempre pulito e nel minor tempo possibile.
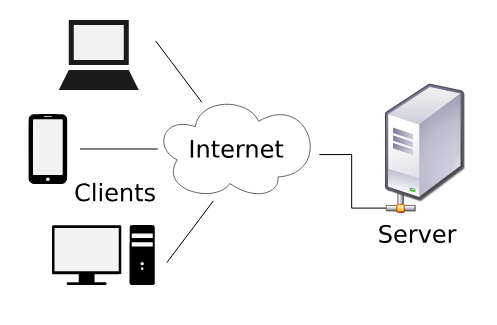
Informazioni di base — Richiesta di una pagina web
Un essere umano, attraverso il proprio dispositivo (desktop, smartphone, tablet), navigando con un web broswser (client), richiede attraverso il protocollo HTTP delle risorse web (HTTP request), fisicamente ospitate su un server, il quale risponderà alla richiesta (HTTP response), fornendo al client la pagina desiderata.
Il server inoltre implementa software e librerie per la gestione degli accessi, allocazione e rilascio delle risorse, condivisione e sicurezza dei dati.
Ad ogni richiesta HTTP corrisponde una risposta dal server (HTTP response):

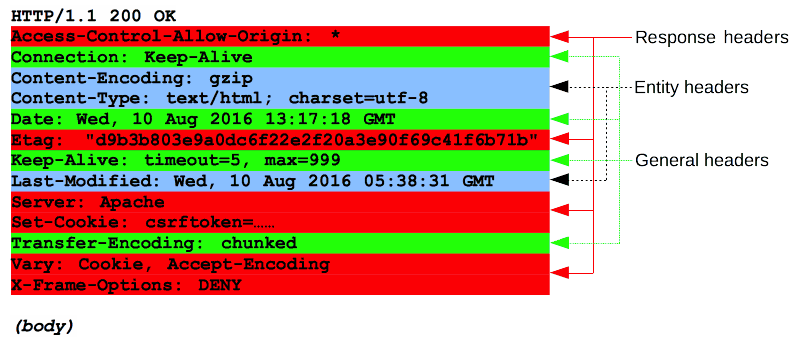
il server risponde fornendo lo stato della richiesta, più altre informazioni e se lo status è 200 OK, avremo il resto della pagina:
<!DOCTYPE html>
<html>
<head>
<title>HTML Examples</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
</head> <body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
<img src="w3schools.jpg" width="104" height="142">
</body>
</html>
Il codice che andremo a scrivere per realizzare il nostro web scraper, a prescindere dal linguaggio utilizzato, avrà lo scopo di:
1. richiedere pagine web al web-server, con relativa risposta
2. effettuare il parsing dell’html attraverso un parser (ad esempio in Python “lxml” o “html.parser”)
3. identificare specifici target (es. <div class=”row”>)
4. manipolare i costrutti ottenuti al fine di estrarre il dato
5. raccogliere il dato,
6. produrre una collection di dati organizzati in uno specifico formato (xls, csv, txt xlm, database, ecc.).

Poche righe di codice e strumenti di base
Innumerevoli sono i dettagli tecnici legati ai tools che usiamo per fare web scraping, quando mal gestiti, possono aprire la strada a situazioni problematiche che possono andare dal semplice ban dell’ip, fino a dover affrontare (nella peggiore delle ipotesi) vere e proprie dispute legali.
Immaginiamo di dover acquisire i dati relativi a 20.000 prodotti, presenti sull’e-commerce di un nostro fornitore, estraendoli per categoria merceologica, il sito web mostra 6 prodotti per pagina, generando 3333 pagine ca. di prodotti.
Il nostro e-commerce start url: Link demo test.
Ipotizziamo di gestire l’estrazione utilizzando un notebook Jupyter con Python, Beautiful Soup e Pandas.
Semplificando “notevolmente” utilizziamo il link di un sito testper lo scraping (attenzione utilizziamo in questo esempio solo il link demo e non il tool proposto da webscraper.io)
[gist id=444e8166dda532cd8d4b573bca106424]
Il codice volutamente brutale e prolisso, mette in risalto la potenza concentrata in poche righe, ma ci porta subito a compiere delle riflessioni approfondite.
Nell’esempio citato parliamo di 3.333 pagine e 20.000 prodotti, ovvero circa 23.333 richieste HTTP da fare al server.
Nella migliore delle ipotesi, richieste di questo tipo vanno incontro a Firewall messi a protezione del server, per ridurre bandwidth overload, downtime, picchi sull’infrastruttura, soprattutto se provenienti da un client singolo o singolo IP, ma anche monitorare e bloccare task ripetitivi e/o rilevare attività di scraping attraverso Honeypots (trappole realizzate ad hoc).
Sia nel caso di web server a spazio, banda e processi limitati, sia nel caso di soluzioni cloud a consumo, come Azure, Aws, ecc., il rischio di generare con il nostro operato veri e propri danni è sicuramente elevato.
Iniziare con un’ottimizzazione responsabile e non dannosa
robots.txt — Il passo più elegante da compiere è la lettura del robots.txt.
La maggior parte dei siti web, che hanno comunicato a Google la struttura del sito web attraverso sitemap.xml (in Search Console), sono anche dotati di file robots.txt.
In questo file vengono indicate ai crawler, le aree del sito web da sottoporre a scansione, ma anche quelle da non tracciare.
Ad esempio prendiamo in considerazione il file robots.txt di levelzero.it:
User-agent: * #qualsiasi user-agent Disallow: /cgi-bin #non scansionare Disallow: /wp-admin #non scansionareSitemap: http://levelzero.it/sitemap_index.xml
Il file robots.txt ci dice che qualsiasi user-agent* può scansionare qualsiasi cosa, tranne i folder indicati dopo il disallow, inoltre in basso troviamo il percorso della sitemap.xml.
Quindi sappiamo dove, il proprietario del sito web, vuole che non si vada ad effettuare scansioni.
* user agent è un’applicazione installata sul computer dell’utente che si connette ad un processo server. Esempi di user agent sono i browser web.
Errori, Timeout & Sleep — Il tempo che intercorre fra HTTP Request ed HTTP Response, può durare da millisecondi a secondi.
Le richieste HTTP non vanno tutte a buon fine, il server restituisce un codice di risposta in base al tipo di errore ricevuto, inoltre potremmo anche trovarci in presenza di Server Connection Timeout, ovvero assenza di connessione al server, il server non è disponibile.
https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
Per evitare che il nostro software di web scraping, in presenza di situazioni come HTTPError, Timeout, TooManyRedirects, RequestException, protragga per un tempo indefinito l’esecuzione di alcune richieste HTTP, è assolutamente necessario gestire le eccezioni, i timeout e gli errori.
Dopo aver importato le librerie necessarie, decidiamo con un ciclo for di tentare n volte a ripetere le richieste, prevedendo il verificarsi delle situazioni più comuni.
In Python il modulo Request, attraverso il metodo raise_for_status(), restituisce il codice della HTTP Response che possiamo gestire attraverso le eccezioni. Successivamente con il metodo sleep() possiamo interrompere, per poi riprendere lo statement dopo una pausa di n secondi.
[gist id=e1d379fc41be1ccd00bdd57de77e3833]
Il codice del nostro web scraper ha subito una prima ottimizzazione in presenza di HTTP Response, diverse dallo status 200 OK.
Ma non è ancora sufficiente, in quanto dobbiamo comunque gestire un numero elevato di HTTP Request.
Richieste asincrone e/o processi in multi-trading
Un approccio gradevole potrebbe essere quello di effettuare richieste asincrone e/o con processi in multi-trading, intervallando ogni operazione con il metodo sleep() per non stressare eccessivamente il server. Degno di approfondimento è progetto Japronto.
Parsing targettizzato
Immaginiamo di dover effettuare il parsing di una categoria e-commerce con i rispettivi prodotti. Perchè effettuare il parsing di tutta la pagina, quando possiamo individuare un target di riferimento, circoscritto a quello che ci interessa?
Ad esempio l’utilizzo di SoupStrainer di BeautifulSoup, consente di circoscrivere l’operazione di parsing solo ad alcuni specifici tag html e non a tutta la pagina.
import requests
import time #per misurare il tempo di esecuzione degli statemant
import urllib.request
from bs4 import BeautifulSoup, SoupStrainert0 = time.time()
link = "https://levelzero.it"
page = requests.get(link, timeout=5)
#request = urllib.request.Request(link)
#contents = page.content
html = urllib.request.urlopen(request).read()
o_page = SoupStrainer("section", attrs={'id':'g-subfeature'})
soup = BeautifulSoup(html, 'html.parser', parse_only=o_page)
t1 = time.time()print("Durata statement: {} secondi".format(t1-t0))
Senza SoupStrainer
import requests
import time #per misurare il tempo di esecuzione degli statemant
import urllib.request
from bs4 import BeautifulSoupt0 = time.time()
link = "https://levelzero.it"
page = requests.get(link, timeout=5)
#request = urllib.request.Request(link)
#contents = page.content
html = urllib.request.urlopen(request).read()soup = BeautifulSoup(html, 'html.parser')
t1 = time.time()print("Durata statement: {} secondi".format(t1-t0))
User Agent e Headers random + Proxy rotation
In Python troviamo diverse librerie per restare anonimi, alcune consento di randomizzare user agent e headers, altre grazie all’utilizzo di un proxy dinamico (proxy rotation) permettono di simulare HTTP Request diversificate provenienti da ip diversi.
Queste tecniche possono essere utilizzate per restare anonimi, effettuando un numero infinito di HTTP Request, senza rischiare di essere bloccati magari da un firewall.
Conclusioni sul web scraping
- L’utilizzo di un processo di web scraping su un sito web, può avvenire solo se le condizioni di utilizzo ci consentono di acquisire dati in maniera automatizzata.
- Qualora le condizioni di utilizzo di un sito web consentano pratiche di web scraping, i processi automatizzati messi in opera per l’acquisizione dei dati, non devono pregiudicare in alcuno modo il sito web stesso, generando ad esempio problemi di bandwidth overload, downtime, picchi sull’infrastruttura.
- Non è possibile utilizzare il web scraping, quando le condizioni di utilizzo del sito web, vietano espressamente l’utilizzo di procedure automatizzate per l’acquisizione di dati e sicuramente quando i dati in oggetto sono tutelati dalla normativa di un determinato Stato (ad esempio GDPR).
ATTENZIONE: nelle condizioni di utilizzo di molti siti web, il web scraping non viene menzionato, molto spesso per mancata conoscenza di questa procedura. Dobbiamo in ogni caso utilizzare questa tecnica con i dovuti accorgimenti, evitando di effettuare operazioni
Link:
https://www.scrapehero.com
https://en.wikipedia.org/wiki/Web_scraping
https://it.wikipedia.org/wiki/Crawler
https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages
https://medium.freecodecamp.org/million-requests-per-second-with-python-95c137af319
https://myshell.co.uk/blog/2017/06/python-get-ip-from-http-request-using-the-requests-module/
https://codelike.pro/create-a-crawler-with-rotating-ip-proxy-in-python/
https://pybay.com/site_media/slides/raymond2017-keynote/process.html
Documentazione
http://docs.python-requests.org/en/master/user/quickstart/
Modulo Request HTTPError, Timeout, TooManyRedirects, RequestException
https://stackoverflow.com/questions/16511337/correct-way-to-try-except-using-python-requests-module
Book:
– Web Scraping with Python. Collecting data from the modern web — Ryan Mitchell
– Pandas, Python for Data Analysis. Data wrangling with Pandas, Numpy and Ipython — Wes McKinney
